原文網址:http://yjhyjhyjh0.pixnet.net/blog/post/411468760-spark-rdd-%28resilient-distributed-datasets%29-%E8%A9%B3%E7%B4%B0%E5%9C%96%E6%96%87%E4%BB%8B
RDD(Resilient Distributed Datasets)
MapReduce 成功的在大資料(Big Data)的分散式環境下分析運算資料
然而在某些運算或演算法執行下 MapReduce 就顯得不夠力
舉凡最著名的兩個場景
1.迭代式運算(Iterative Jobs) : 如:機器學習演算法, 分類演算法
(這類演算法要不斷執行同個步驟 且每個步驟以上個結果為輸入)
2.交互式分析(Iterative Analyst) : 如:馬克霍夫矩陣
(求長遠時間之後的平衡狀態為何)
為什麼MapReduce不適合執行上述之場景呢?由下圖解釋
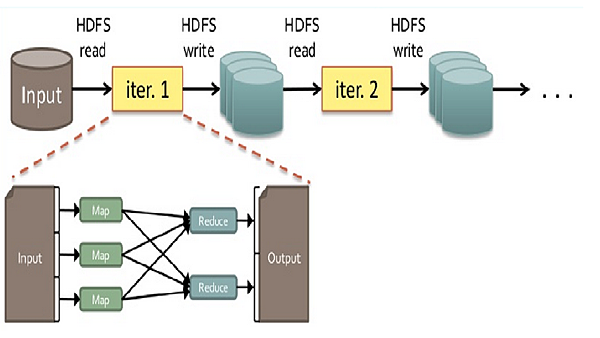
上圖敘述一般預設的狀態下 MapReduce 執行過程中,必須將工作的結果存回HDFS中,
但是在需要不斷運算的場景下 (像是要重複算上萬次得到結果), 這一來一往的I/O將十分龐大
原因其實是 MapReduce一開始就不是為了這些場景而去設計的,自然會有這些問題,其實是我們的需求增加而產生這樣的問題。
上述問題讓我發現MapReduce缺少一個重要的要素
有效的資料共享(efficient data sharing)
而Spark即提出一個能解決的問題的效果
In-Memory Data Processing and Sharing
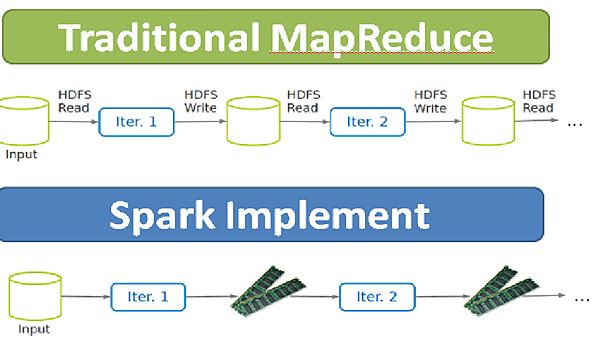
若是能將中間運算結果直間存於Memory 中 ,那自然就會快速許多
而要如何設計一個 高容錯(tolerant) 高效能(efficient)的結構?
這是RDD的設計概念由來Resilient Distribute Datasets
---------------------------------------RDD介紹----------------------------------------------------
首先先看一下RDD長什麼樣子
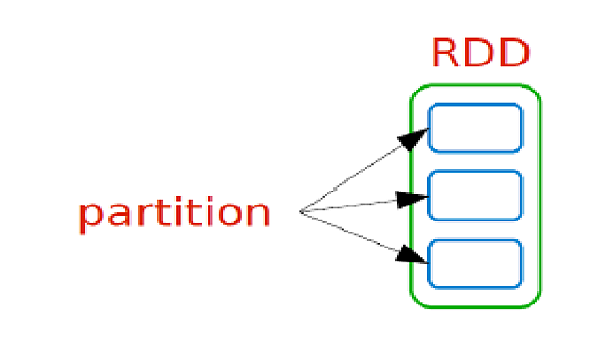
Partition是資料分片 可能會在不同的機器上
而RDD則是指一個資料分片的集合 大多數情況都存於Memory中 (即一個RDD裡會有多個在不同機器上的partition)
RDD可以容錯也是因為他把資料分成許多片段,存在不同的機器上面。
Spark的核心數據模型是RDD,Spark將常用的大數據操 作都轉化成為RDD的子類。
○輸入: ◉ 在Spark程序運行中,數據從外部數據空間(如分佈式存儲:textFile讀 取HDFS等,parallelize方法輸入Scala集合或數據)輸入Spark,數據 進入Spark運行時數據空間,轉化為Spark中的數據塊,通過 BlockManager進行管理。
○運行: ◉ 在Spark數據輸入形成RDD後便可以通過變運算子,如filter等,對數據 進行Transformation並將RDD轉化為新的RDD,通過Action,觸發 Spark提交作業。如果數據需要復用,可以通過Cache算子,將數據緩 存到內存。
○輸出: ◉ 程序運行結束數據會輸出Spark運行時空間,存儲到分佈式存儲中(如 saveAsTextFile輸出到HDFS),或Scala數據或集合中(collect輸出到 Scala集合,count返回Scala int型數據)。
RDD是不可變性(immutable)
○當資料轉換成RDD物件後,那個RDD物件基本就處於被封裝的狀 態,如果要進行filter或map的動作,會在使用另外一個RDD來封 裝改變後的資料。
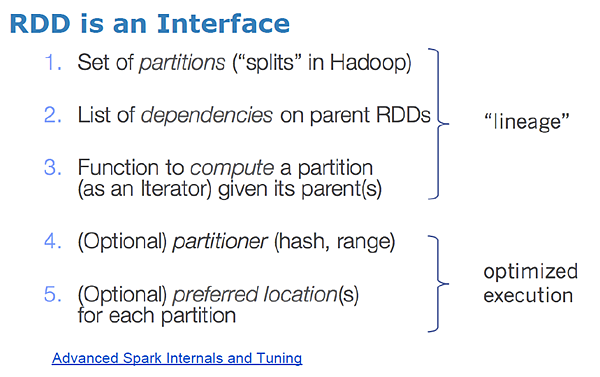
照官方文件說法 實際上一個RDD會有以上五樣東西
1.每個partition位置
2.與父RDD的依賴關西
3.父RDD經過何種運算得到此RDD的 (function)
這裡是RDD的產生過程,如果RDD遺失了,可以從父RDD再把RDD生回來。
以上三樣在RDD概念裡主要是為了實現 血統關係(lineage) 主要是為了容錯而設計的 在稍後的RDD容錯機制會詳細敘述,先來看看RDD是如何被使用來運算的
RDD有兩種運算方式
1.Transformations: 懶惰(lazy)運算 會製造出新的RDD
2.Action: 執行一個運算並return結果或是存到Storage裡
Transformations和Action超級重要

圖片來源: https://www.jianshu.com/p/dfb4007b9b7f
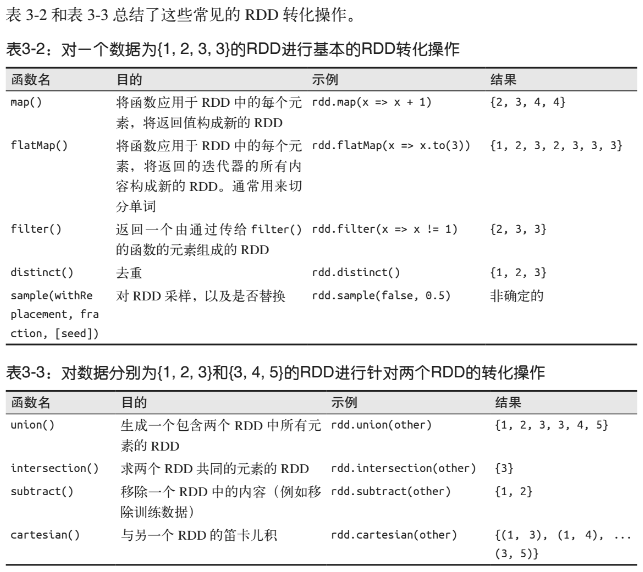

以上列了相關運算是怎麼分的
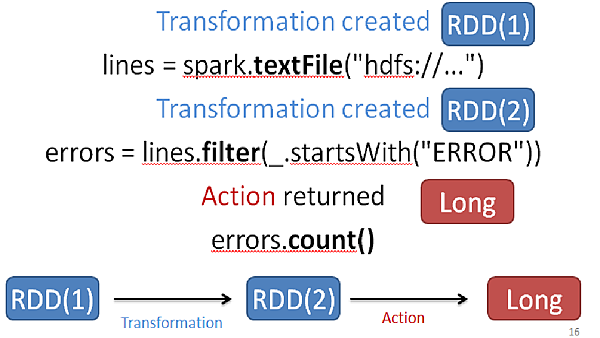
以上是一個詳細的圖解運算過程中 其實會不斷的產生新的RDD 最後在生成結果
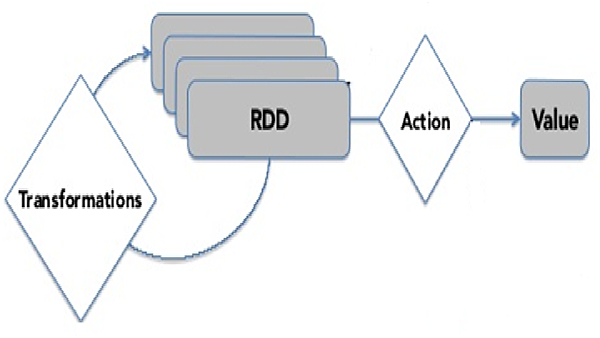
所以整個RDD執行不外乎此圖
-----------------------------RDD容錯機制---------------------------------------------
清楚了RDD運算過程後
必須提到他是如何容錯的
場景如下
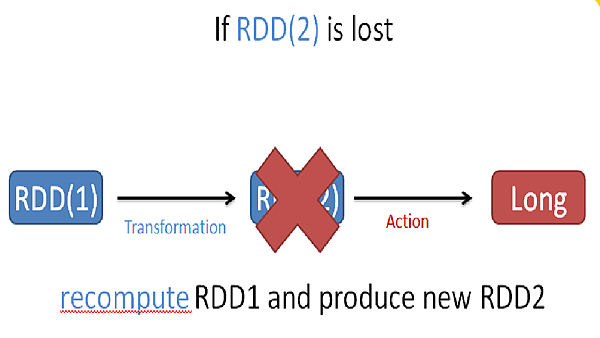
當有RDD遺失時
會根據前面提到的血統關係(lineage)來重新計算所需RDD
所以實際上Spark是沒有replication機制
但明顯的要是 失去的RDD剛好是要計算出結果的1萬次運算的9999次怎麼辦?
那不是等於要重算嗎?
所以Spark還提供一個客製化的機制CheckPoint
由使用者自己設計儲存點 在這點的RDD會存於Storage 以免遺失
所以實際上Spark經由lineage 與 CheckPoint來執行容錯
-------------------------------------------結論-------------------------------------------
Spark的核心技術是RDD
所以要了解Spark 要先理解RDD是如何設計的 跟 優勢為何
整個Spark的工作流程如下
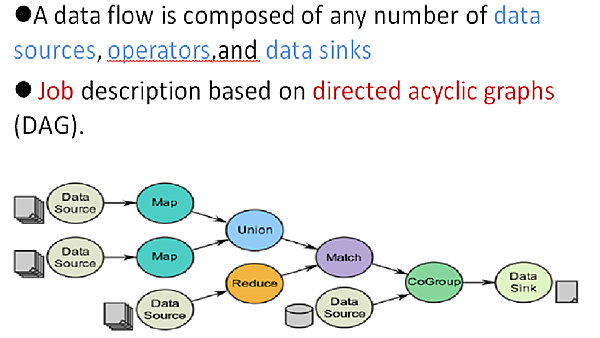
官方網站: http://spark.apache.org/docs/latest/index.html
參考資料 :https://blog.51cto.com/36006798/1854802
https://bitnine.net/blog-computing/understanding-of-spark-part-2/
https://www.jianshu.com/p/4ff6afbbafe4
https://ithelp.ithome.com.tw/articles/10186282
https://medium.com/pyradise/%E4%B8%8A%E5%82%B3%E6%AA%94%E6%A1%88%E5%88%B0google-colab-dd5369a0bbfd
RDD(Resilient Distributed Datasets)
MapReduce 成功的在大資料(Big Data)的分散式環境下分析運算資料
然而在某些運算或演算法執行下 MapReduce 就顯得不夠力
舉凡最著名的兩個場景
1.迭代式運算(Iterative Jobs) : 如:機器學習演算法, 分類演算法
(這類演算法要不斷執行同個步驟 且每個步驟以上個結果為輸入)
2.交互式分析(Iterative Analyst) : 如:馬克霍夫矩陣
(求長遠時間之後的平衡狀態為何)
為什麼MapReduce不適合執行上述之場景呢?由下圖解釋
上圖敘述一般預設的狀態下 MapReduce 執行過程中,必須將工作的結果存回HDFS中,
但是在需要不斷運算的場景下 (像是要重複算上萬次得到結果), 這一來一往的I/O將十分龐大
原因其實是 MapReduce一開始就不是為了這些場景而去設計的,自然會有這些問題,其實是我們的需求增加而產生這樣的問題。
上述問題讓我發現MapReduce缺少一個重要的要素
有效的資料共享(efficient data sharing)
而Spark即提出一個能解決的問題的效果
In-Memory Data Processing and Sharing
若是能將中間運算結果直間存於Memory 中 ,那自然就會快速許多
而要如何設計一個 高容錯(tolerant) 高效能(efficient)的結構?
這是RDD的設計概念由來Resilient Distribute Datasets
---------------------------------------RDD介紹----------------------------------------------------
首先先看一下RDD長什麼樣子
Partition是資料分片 可能會在不同的機器上
而RDD則是指一個資料分片的集合 大多數情況都存於Memory中 (即一個RDD裡會有多個在不同機器上的partition)
RDD可以容錯也是因為他把資料分成許多片段,存在不同的機器上面。
Spark的核心數據模型是RDD,Spark將常用的大數據操 作都轉化成為RDD的子類。
○輸入: ◉ 在Spark程序運行中,數據從外部數據空間(如分佈式存儲:textFile讀 取HDFS等,parallelize方法輸入Scala集合或數據)輸入Spark,數據 進入Spark運行時數據空間,轉化為Spark中的數據塊,通過 BlockManager進行管理。
○運行: ◉ 在Spark數據輸入形成RDD後便可以通過變運算子,如filter等,對數據 進行Transformation並將RDD轉化為新的RDD,通過Action,觸發 Spark提交作業。如果數據需要復用,可以通過Cache算子,將數據緩 存到內存。
○輸出: ◉ 程序運行結束數據會輸出Spark運行時空間,存儲到分佈式存儲中(如 saveAsTextFile輸出到HDFS),或Scala數據或集合中(collect輸出到 Scala集合,count返回Scala int型數據)。
RDD是不可變性(immutable)
○當資料轉換成RDD物件後,那個RDD物件基本就處於被封裝的狀 態,如果要進行filter或map的動作,會在使用另外一個RDD來封 裝改變後的資料。
照官方文件說法 實際上一個RDD會有以上五樣東西
1.每個partition位置
2.與父RDD的依賴關西
3.父RDD經過何種運算得到此RDD的 (function)
這裡是RDD的產生過程,如果RDD遺失了,可以從父RDD再把RDD生回來。
以上三樣在RDD概念裡主要是為了實現 血統關係(lineage) 主要是為了容錯而設計的 在稍後的RDD容錯機制會詳細敘述,先來看看RDD是如何被使用來運算的
RDD有兩種運算方式
1.Transformations: 懶惰(lazy)運算 會製造出新的RDD
2.Action: 執行一個運算並return結果或是存到Storage裡
Transformations和Action超級重要
圖片來源: https://www.jianshu.com/p/dfb4007b9b7f
以上列了相關運算是怎麼分的
以上是一個詳細的圖解運算過程中 其實會不斷的產生新的RDD 最後在生成結果
所以整個RDD執行不外乎此圖
-----------------------------RDD容錯機制---------------------------------------------
清楚了RDD運算過程後
必須提到他是如何容錯的
場景如下
當有RDD遺失時
會根據前面提到的血統關係(lineage)來重新計算所需RDD
所以實際上Spark是沒有replication機制
但明顯的要是 失去的RDD剛好是要計算出結果的1萬次運算的9999次怎麼辦?
那不是等於要重算嗎?
所以Spark還提供一個客製化的機制CheckPoint
由使用者自己設計儲存點 在這點的RDD會存於Storage 以免遺失
所以實際上Spark經由lineage 與 CheckPoint來執行容錯
-------------------------------------------結論-------------------------------------------
Spark的核心技術是RDD
所以要了解Spark 要先理解RDD是如何設計的 跟 優勢為何
整個Spark的工作流程如下
官方網站: http://spark.apache.org/docs/latest/index.html
參考資料 :https://blog.51cto.com/36006798/1854802
https://bitnine.net/blog-computing/understanding-of-spark-part-2/
https://www.jianshu.com/p/4ff6afbbafe4
https://ithelp.ithome.com.tw/articles/10186282
https://medium.com/pyradise/%E4%B8%8A%E5%82%B3%E6%AA%94%E6%A1%88%E5%88%B0google-colab-dd5369a0bbfd
留言
張貼留言